Recommender systems#
Nowadays, recommender systems are used in a variety of areas such as e-commerce platform or media delivery services (movies, music, etc.). It has been notably used in the DigitAlu project to recommend alloys produced by Constellium to part manufacturers.
Recommender system are usually categorized in two categories: content-based filtering or collaborative filtering :
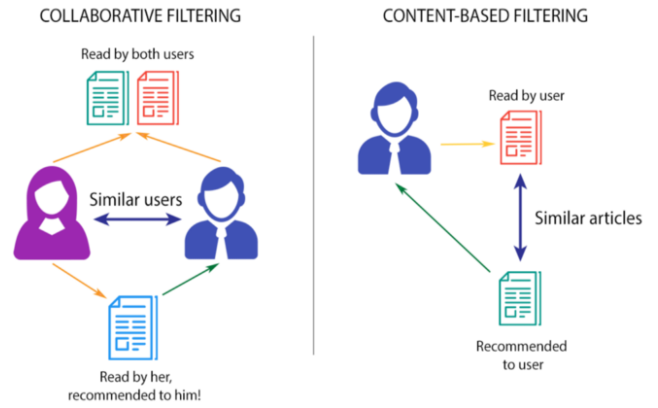
Content-based filtering#
Content-based filtering makes recommendations based on user preferences for product features. It relies mainly on similarities between features of items. Thus, as stated by the type of this filtering, that is “Content-based”, the recommendation will be based on the actual “Content” of the items. This “Content” is usually expressed in term of features that characterize the product. The feature of a product could be for example the size, the category, the color, etc.. any properties of the product that can be quantified. The products that have the most overlapping features with the user interest (profile) are what’s recommended. While some features for a product may be clearly defined (e.g. size, color), sometimes more abstract features can be attributed to a product in which case a fair amount of domain knowledge from the people attributing these features is required. This is the case for example when evaluating a property that is not easily quantifiable (e.g. category of a movies, ease of use, …).
Collaborative filtering#
Collaborative filtering is based on the assumption that people like things similar to other things they like, and things that are liked by other people with similar taste (collaboration). It predicts users’ preferences as combination of other users’ preferences. Therefore, this type of filtering doesn’t need anything else except user’s historical preference on a set of items. The key advantage is that it is therefore capable of accurately recommending complex items without requiring an “understanding” of the item itself. In terms of user preference, it is usually expressed by two categories: explicit data and implicit data. Explicit data could be for example a rate given by a user to an item. This is the most direct feedback from users to show how much they liked an item. Implicit data suggests users preferences indirectly, such as page views, clicks, purchases.
Both methods have limitations. Content-based filtering can recommend a new item but needs more data of user preference in order to incorporate best match. Similarly, collaborative filtering needs larger dataset with active users who rated a product before in order to make accurate predictions (cold start problem) and thus has difficulty recommending new items. Nonetheless, collaborative filtering is the most popular method since by leveraging other users’ experiences through the provided explicit and implicit data the the recommender system can make better predictions. However, combination of these different methods are called Hybrid systems and are increasingly popular.
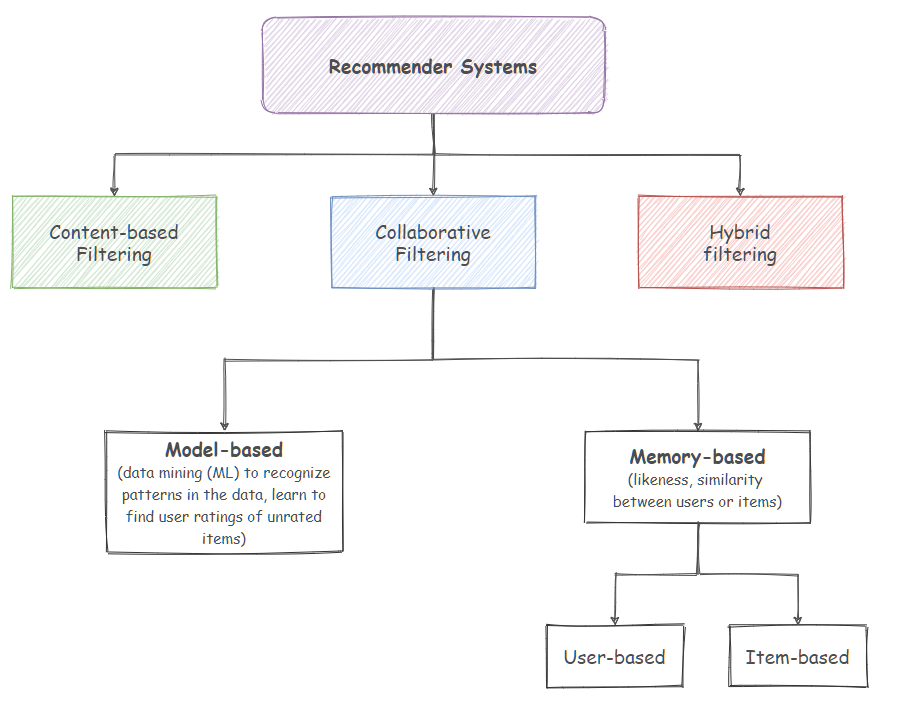
Collaborative filtering is more widely used and has been more developed than content-based filtering. It can further be broken down in two categories: memory and model based algorithm. This distinction can be thought as coming from the distinction we can make between parametric and non-parametric approaches.
Note
Y = f(x): If f() is a function that maps input variables X to output variables Y, then a non-parametric method is well suited when we cannot make strong assumption about the underlying form of the mapping function. Whereas, if we can simplify the function to a know form (determine the parameters) then a parametric method is preferred. Thus, a model-based algorithm can be thought as being similar to a parametric model in the sense that the model is trying to learn and optimize the function to a known form, while memory-based algorithm does not make any assumption about the form of the mapping function, and thus are considered non-parametric.
Memory-based#
Memory-based collaborative filtering utilizes the entire user-item data to generate predictions. The system uses statistical methods to search for a set of users who have similar transactions history to the active user. This method is also called nearest-neighbor (likeness, similarity). This approaches can be divided into two main sections: user-based and item-based filtering. A user-based filtering takes a particular user, find users that are similar to that user based on similarity of ratings, and recommend items that those similar users liked. In contrast, item-based filtering will take an item, find users who liked that item, and find other items that those users or similar users also liked. It takes items and outputs other items as recommendations.
User-based recommendations: “Users who are similar to you also liked…”
Item-based recommendations: “Users who liked this item also liked …”
The advantages of memory-based collaborative filtering is that they are easy to implement and able to accommodate the new data with ease. However, memory-based collaborative filtering has decreasing performance in data with high sparsity and have limited scalability for large datasets.
Technically speaking, a memory-based algorithm is a non-parametric approach, i.e. the method doesn’t try to optimize or learn a parameter. Instead, The nearest-neighbor are calculated by using simple cosine similarity or correlations coefficients, which are only based on arithmetic operations.
Model-based#
Model-based collaborative filtering provides recommendations by developing a model from user ratings and predict unrated items. It is also capable of handling the problem of sparsity and scalability better than memory-based. The modeling process is conducted by machine learning techniques such as classification, clustering, and rule-based approach. However, model-based approach requires a great resource, such as time and memory, to develop the model and may lose information when using dimensionality reduction.
One of the most popular technique for model-based collaborative filtering is the Matrix Factorization, as it became widely known during the Netflix prize challenge.
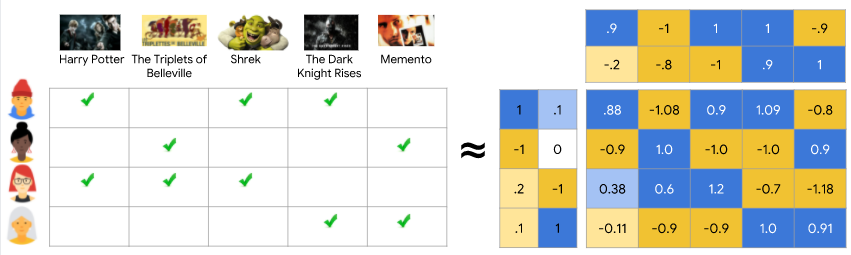
The underlying principle of Matrix Factorization is to characterize both items and users on latent features inferred from the rating/usage pattern. For example, we can decompose the interaction matrix above into the product of two lower dimensionality rectangular matrices: a matrix from the point of views of users (users space) with an arbitrary number of features (here 2) and from the point of view of items (items space) with the same number of features. When multiplying these two matrices, we get a very close approximation to the original matrix.
The extracted latent factors (features) could mean anything, and nobody could tell if one of those factor correspond really to a particular interpretable feature. For example ,maybe a latent factor corresponds to whether or not a particular actor was in the movie. Although we can’t interpret those latent factors, the key is that we can build recommendation by using the dot product of the user and item representation (respective vectors of latent factor).